调教 DeepSeek周末刷屏

 调教
调教
作家汪友若
刚刚昔时的周末,全球AI领域出现了一位出东说念主料念念的价钱颠覆者。它并非出生于科技巨头或互联网巨头,而与著名量化私募幻方量化有着密切的关系。
12月26日晚间,AI公司杭州深度求索(DeepSeek)负责上线全新系列模子DeepSeek-V3首个版块并同步开源。公司称,DeepSeek-V3多项评测收获杰出了Qwen2.5-72B和Llama-3.1-405B等其他开源模子,并在性能上和寰宇顶尖的闭源模子GPT-4o以及Claude-3.5-Sonnet不分昆仲。
而况,DeepSeek将模子API做事订价退换为每百万输入tokens0.5元(缓存掷中)/2元(缓存未掷中),每百万输出tokens8元,以期大概捏续地为寰球提供更好的模子做事。DeepSeek还决定为全新模子建树长达45天的优惠价钱体验期:26日起至2025年2月8日,DeepSeek-V3的API做事价钱仍然是每百万输入tokens0.1元(缓存掷中)/1元(缓存未掷中),每百万输出tokens2元。
老婆偷情广发证券筹画机团队12月29日发布讲演称,通过有限的实测欺压,偷窥偷拍该团队发现,DeepSeek总体智商与其他大模子相配,但在逻辑推理和代码生成领域具有本身特色。而况DeepSeek-V3通过数据与算法层面的优化,大幅进步算力期骗服从,终清亮协同效应。
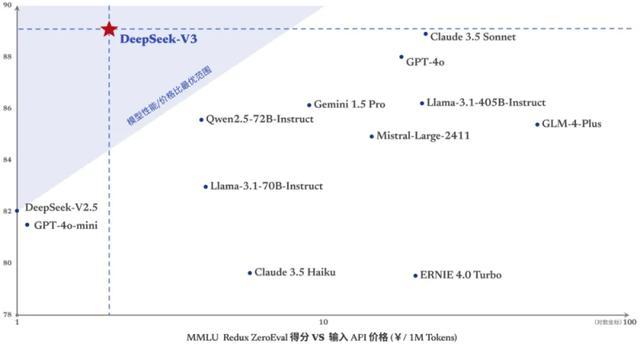
广发证券称,在大范畴MoE模子的纯熟中,DeepSeek-V3领受了高效的负载平衡战略、FP8搀杂精度纯熟框架以及通讯优化等一系列优化范例,权贵裁减了纯熟资本。DeepSeek讲明了模子欺压不仅依赖于算力进入,即使在硬件资源有限的情况下,依托数据与算法层面的优化翻新,仍然不错高效期骗算力,终了较好的模子欺压。
曾是OpenAI首创成员之一的AI科学家Andrej Karpathy评价称:“今天,一家中国AI公司举手之劳地发布了一个前沿妄言语模子,其仅使用2048块GPU纯熟了2个月,只浪掷了近600万好意思元。当作参考,这种级别的智商本应该需要接近1.6万块的GPU集群调教,而现在正在部署的集群包含的GPU数目却接近10万块。举例,Llama 3405B模子使用了3080万GPU/小时,而DeepSeek-V3模子看起来愈加宽广,却仅使用了280万GPU/小时(筹画量减少了约11倍)。淌若此模子还能通过各项评估,那么这将是资源受限条目下算计与工程智商的高度令东说念主印象深切的展示。”